Ollama CLI tutorial: Running Ollama via the terminal
As a powerful tool for running large language models (LLMs) locally, Ollama gives developers, data scientists, and technical users greater control and flexibility in customizing models.
While you can use Ollama with third-party graphical interfaces like Open WebUI for simpler interactions, running it through the command-line interface (CLI) lets you log responses to files and automate workflows using scripts.
This guide will walk you through using Ollama via the CLI, from learning basic commands and interacting with models to automating tasks and deploying your own models. By the end, you’ll be able to tailor Ollama for your AI-based projects.
Setting up Ollama in the CLI
Before using Ollama in the CLI, make sure you’ve installed it on your system successfully. To verify, open your terminal and run the following command:
ollama --version
You should see an output similar to:

Next, familiarize yourself with these essential Ollama commands:
| Command | Description |
ollama serve | Starts Ollama on your local system. |
ollama create <new_model> | Creates a new model from an existing one for customization or training. |
ollama show <model> | Displays details about a specific model, such as its configuration and release date. |
ollama run <model> | Runs the specified model, making it ready for interaction |
ollama pull <model> | Downloads the specified model to your system. |
ollama list | Lists all the downloaded models. |
ollama ps | Shows the currently running models. |
ollama stop <model> | Stops the specified running model. |
ollama rm <model> | Removes the specified model from your system. |
Essential usage of Ollama in the CLI
This section will cover the primary usage of the Ollama CLI, from interacting with models to saving model outputs to files.
Running models
To start using models in Ollama, you first need to download the desired model using the pull command. For example, to pull Llama 3.2, execute the following:
ollama pull llama3.2
Wait for the download to complete; the time may vary depending on the model’s file size.
Pro tip
If you’re unsure which model to download, check out the Ollama official model library. It provides important details for each model, including customization options, language support, and recommended use cases.
After pulling the model, you can run it with a predefined prompt like this:
ollama run llama3.2 "Explain the basics of machine learning."
Here’s the expected output:

Alternatively, run the model without a prompt to start an interactive session:
ollama run llama3.2
In this mode, you can enter your queries or instructions, and the model will generate responses. You can also ask follow-up questions to gain deeper insights or clarify a previous response, such as:
Can you elaborate on how machine learning is used in the healthcare sector?
When you’re done interacting with the model, type:
/bye
This will exit the session and return you to the regular terminal interface.
Suggested reading
Learn how to create effective AI prompts to improve your results and interactions with Ollama models.
Training models
While pre-trained open-source models like Llama 3.2 perform well for general tasks like content generation, they may not always meet the needs of specific use cases. To improve a model’s accuracy on a particular topic, you need to train it using relevant data.
However, note that these models have short-term memory limitations, meaning the training data is only retained during the active conversation. When you quit the session and start a new one, the model won’t remember the information you previously trained it with.
To train the model, start an interactive session. Then, initiate training by typing a prompt like:
Hey, I want you to learn about [topic]. Can I train you on this?
The model will respond with something like:

You can then provide basic information about the topic to help the model understand:

To continue the training and provide more information, ask the model to prompt you with questions about the topic. For example:
Can you ask me a few questions about [topic] to help you understand it better?
Once the model has enough context on the subject, you can end the training and test if the model retains this knowledge.

Prompting and logging responses to files
In Ollama, you can ask the model to perform tasks using the contents of a file, such as summarizing text or analyzing information. This is especially useful for long documents, as it eliminates the need to copy and paste text when instructing the model.
For example, if you have a file named input.txt containing the information you want to summarize, you can run the following:
ollama run llama3.2 "Summarize the content of this file in 50 words." < input.txt
The model will read the file’s contents and generate a summary:

Ollama also lets you log model responses to a file, making it easier to review or refine them later. Here’s an example of asking the model a question and saving the output to a file:
ollama run llama3.2 "Tell me about renewable energy."> output.txt
This will save the model’s response in output.txt:

Advanced usage of Ollama in the CLI
Now that you understand the essentials, let’s explore more advanced uses of Ollama through the CLI.
Creating custom models
Running Ollama via the CLI, you can create a custom model based on your specific needs.
To do so, create a Modelfile, which is the blueprint for your custom model. The file defines key settings such as the base model, parameters to adjust, and how the model will respond to prompts.
Follow these steps to create a custom model in Ollama:
1. Create a new Modelfile
Use a text editor like nano to create a new Modelfile. In this example, we’ll name the file custom-modelfile:
nano custom-modelfile
Next, copy and paste this basic Modelfile template, which you’ll customize in the next step:
# Use Llama 3.2 as the base model
FROM llama3.2
# Adjust model parameters
PARAMETER temperature 0.7
PARAMETER num_ctx 3072
PARAMETER stop "assistant:"
# Define model behavior
SYSTEM "You are an expert in cyber security."
# Customize the conversation template
TEMPLATE """{{ if .System }}Advisor: {{ .System }}{{ end }}
Client: {{ .Prompt }}
Advisor: {{ .Response }}"""
2. Customize the Modelfile
Here are the key elements you can customize in the Modelfile:
- Base model (FROM). Sets the base model for your custom instance. You can choose from available models like Llama 3.2:
FROM llama3.2
- Parameters (PARAMETER). Control the model’s behavior, such as:
- Temperature. Adjusts the model’s creativity. Higher values like 1.0 make it more creative, while lower ones like 0.5 make it more focused.
PARAMETER temperature 0.9
- Context window (num_ctx). Defines how much previous text the model uses as context.
PARAMETER num_ctx 4096
- System message (SYSTEM). Defines how the model should behave. For example, you can instruct it to act as a specific character or avoid answering irrelevant questions:
SYSTEM “You are an expert in cyber security. Only answer questions related to cyber security. If asked anything unrelated, respond with: ‘I only answer questions related to cyber security.’"
- Template (TEMPLATE). Customize how to structure the interaction between the user and the model. For instance:
TEMPLATE """{{ if .System }}<|start|>system
{{ .System }}<|end|>{{ end }}
<|start|>user
{{ .Prompt }}<|end|>
<|start|>assistant
"""
After making the necessary adjustments, save the file and exit nano by pressing Ctrl + X → Y → Enter.
3. Create and run the custom model
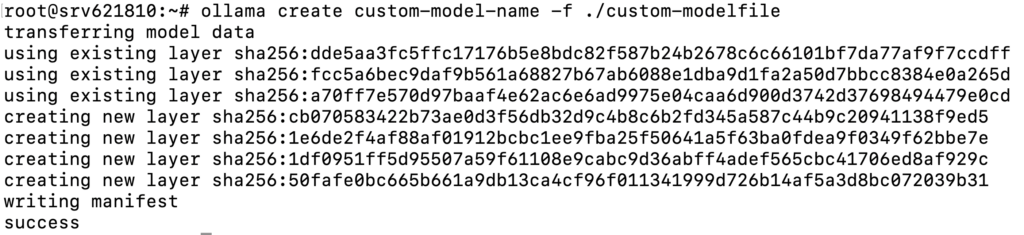
Once your Modelfile is ready, use the command below to create a model based on the file:
ollama create custom-model-name -f ./custom-modelfile
You should see an output indicating the model was created successfully:
After that, run it just like any other model:
ollama run custom-model-name
This will start the model with the customizations you applied, and you can interact with it:

You can continually tweak and refine the Modelfile by adjusting parameters, editing system messages, adding more advanced templates, or even including your own datasets. Save the changes and re-run the model to see the effects.
Automating tasks with scripts
Automating repetitive tasks in Ollama can save time and ensure workflow consistency. By using bash scripts, you can execute commands automatically. Meanwhile, with cron jobs, you can schedule tasks to run at specific times. Here’s how to get started:
Create and run bash scripts
You can create a bash script that executes Ollama commands. Here’s how:
- Open a text editor and create a new file named ollama-script.sh:
nano ollama-script.sh
- Add the necessary Ollama commands inside the script. For instance, to run a model and save the output to a file:
#!/bin/bash # Run the model and save the output to a file ollama run llama3.2 "What are the latest trends in AI?" > ai-output.txt
- Make the script executable by giving it the correct permissions:
chmod +x ollama-script.sh
- Run the script directly from the terminal:
./ollama-script.sh
Set up cron jobs to automate tasks
You can combine your script with a cron job to automate tasks like running models regularly. Here’s how to set up a cron job to run Ollama scripts automatically:
- Open the crontab editor by typing:
crontab -e
- Add a line specifying the schedule and the script you want to run. For example, to run the script every Sunday at midnight:
0 0 * * 0 /path/to/ollama-script.sh
- Save and exit the editor after adding the cron job.
Common use cases for the CLI
Here are some real-world examples of using Ollama’s CLI.
Text generation
You can use pre-trained models to create summaries, generate content, or answer specific questions.
- Summarizing a large text file:
ollama run llama3.2 "Summarize the following text:" < long-document.txt
- Generating content such as blog posts or product descriptions:
ollama run llama3.2 "Write a short article on the benefits of using AI in healthcare."> article.txt
- Answering specific questions to help with research:
ollama run llama3.2 "What are the latest trends in AI, and how will they affect healthcare?"
Data processing, analysis, and prediction
Ollama also lets you handle data processing tasks such as text classification, sentiment analysis, and prediction.
- Classifying text into positive, negative, or neutral sentiment:
ollama run llama3.2 "Analyze the sentiment of this customer review: 'The product is fantastic, but delivery was slow.'"
- Categorizing text into predefined categories:
ollama run llama3.2 "Classify this text into the following categories: News, Opinion, or Review." < textfile.txt
- Predicting an outcome based on the provided data:
ollama run llama3.2 "Predict the stock price trend for the next month based on the following data:" < stock-data.txt
Integration with external tools
Another common use of the Ollama CLI is combining it with external tools to automate data processing and expand the capabilities of other programs.
- Integrating Ollama with a third-party API to retrieve data, process it, and generate results:
curl -X GET "https://api.example.com/data" | ollama run llama3.2 "Analyze the following API data and summarize key insights."
- Using Python code to run a subprocess with Ollama:
import subprocess result = subprocess.run(['ollama', 'run', 'llama3.2', 'Give me the latest stock market trends'], capture_output=True) print(result.stdout.decode())

Conclusion
In this article, you’ve learned the essentials of using Ollama via CLI, including running commands, interacting with models, and logging model responses to files.
Using the command-line interface, you can also perform more advanced tasks, such as creating new models based on existing ones, automating complex workflows with scripts and cron jobs, and integrating Ollama with external tools.
We encourage you to explore Ollama’s customization features to unlock its full potential and enhance your AI projects. If you have any questions or would like to share your experience using Ollama in the CLI, feel free to use the comment box below.
Ollama CLI tutorial FAQ
What can I do with the CLI version of Ollama?
With the CLI version of Ollama, you can run models, generate text, perform data processing tasks like sentiment analysis, automate workflows with scripts, create custom models, and integrate Ollama with external tools or APIs for advanced applications.
How do I install models for Ollama in the CLI?
To install models via the CLI, first make sure you have downloaded Ollama on your system. Then, use the ollama pull command followed by the model name. For example, to install Llama 3.2, execute ollama pull llama3.2.
Can I use multimodal models in the CLI version?
While it’s technically possible to use multimodal models like LlaVa in Ollama’s CLI, it’s not convenient because the CLI is optimized for text-based tasks. We suggest using Ollama with GUI tools to handle visual-related work.

Ariffud is a Technical Content Writer with an educational background in Informatics. He has extensive expertise in Linux and VPS, authoring over 200 articles on server management and web development. Follow him on LinkedIn.